

What I Learned: The March Towards Massive Context Windows
Context window growth is flying under the radar, but its impact will be massive.


Last week, AI startup Anthropic released their new ChatGPT competitor Claude 3. I had used Claude 2 a little bit last year because I found it was better at writing than ChatGPT, but ultimately it was still underwhelming and lacked other key features provided by OpenAI's flagship model.
However, Claude 3 might be different. There are a lot of tests and comparisons online so I won't be diving into that. But I do want to discuss a certain point that I think is going under the radar - that is, the rapidly growing context windows that these models have.
If you're unaware, the context window is basically the amount of text, images or other files the model can work with in a single conversation. After crossing the maximum context window, not only are details forgotten, but the model often starts to get confused and performance drops.
Context windows are measured by "tokens" which can be understood as just a unit of data. A token is loosely 3/4 of a word.
For some background, here are the context windows of widely used LLM models:
Models Context Window Input Cost / 1M tokens Output Cost / 1M tokens Claude 2.1 200K $8.00 $24.00 Claude 3 Opus 200K $15.00 $75.00 Claude 3 Sonnet 200K $3.00 $15.00 Claude 3 Haiku 200K $0.25 $1.25 GPT-4 Turbo 128K $10.00 $30.00 Gemini 1.5 Pro 128K N/A N/A Claude 2 100K $8.00 $24.00 Claude Instant 100K $0.80 $2.40 GPT-4-32k 32K $60.00 $120.00 Gemini Pro 32K $0.125 $0.375 Mistral Medium 32K $2,7 $8.1 Mistral Large 32K $8.00 $24.00 GPT-3.5 Turbo 16K $0.5 $1.5 Mistral Small 16K $2.00 $6.00 GPT-4 8K $30.00 $60.00 GPT-3.5 Turbo Instruct 4K GPT-3.0 2K
I've gone ahead and added release dates to these models and then plotted it below.
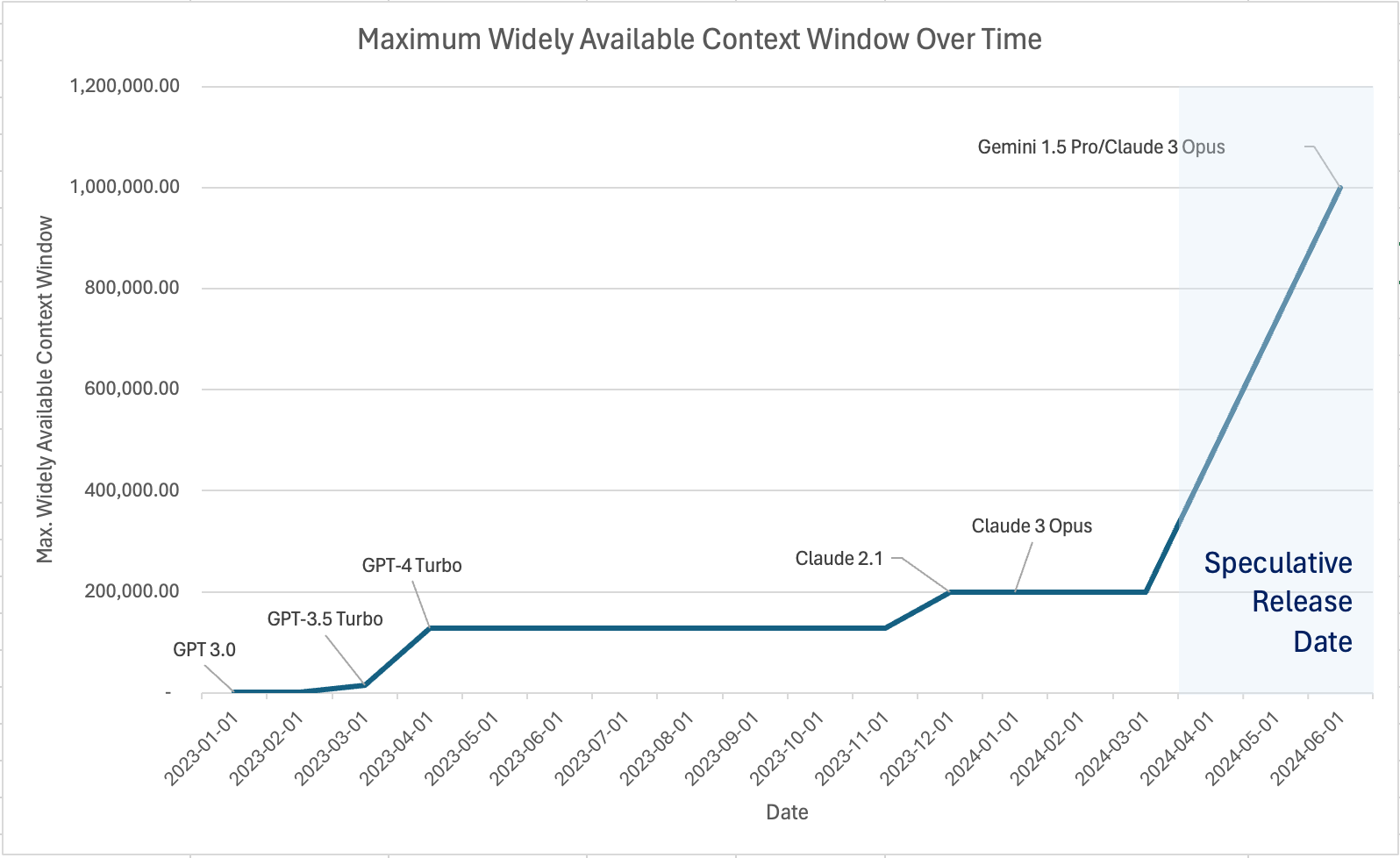
Now, it's important to note that 1M token context windows aren't widely available yet. But, Google has already released their 1M model to select developers and journalists. Anthropic also claims their Opus model is capable of handling 1M tokens but that they are planning to release access to it gradually.
Frankly though, the release dates don't matter since, as I will explain, we are already on track to reach sizes that would be revolutionary.
Since March last year, we have seen a roughly 50x increase in available context windows. It's likely that we will see another 10x increase within the year if Google's 1M is released to the public. Google also claims to be testing 10M context windows, and there are public research papers discussing 1 Billion token context windows.
For some background, the entire Harry Potter series is roughly 1.1 million words. So an LLM like Claude 3 can already ingest the first 6 books of the series in a single conversation and then tell you about a specific scene from book 4 with nearly perfect recall.
When you start to consider the possibility of 1 billion token windows, these LLMs would begin to reach a point where it's difficult to predict just how useful they could be. An organization would not need to spend time training a model. The model could sit outside the organization on Google's cloud, for example, and just be fed the organization's entire accounting system - the historical data and code it runs on - managing and using the system as needed.
In a field like accounting where there would be many examples within the system of how something should be performed, it would not be difficult for the model to do the same thing in a fraction of the time.
So, although not as sexy as OpenAI's Sora video generation, I think these continuous breakthroughs in context window length have even more profound implications.
Not Slowing Down
Emails between a key OpenAI employee (rumoured: Andrej Karpathy), and Elon Musk were released a couple of weeks ago by OpenAI regarding the ongoing lawsuit between the two parties. While the main point behind the emails wasn't to discuss the expected rate of progress in context windows or even AI in general, I found one snippet particularly relevant.
I also strongly suspect that compute horsepower will be necessary (and possibly even sufficient) to reach AGI. If historical trends are any indication, progress in AI is primarily driven by systems - compute, data, infrastructure. The core algorithms we use today have remained largely unchanged from the ~90s. Not only that, but any algorithmic advances published in a paper somewhere can be almost immediately re-implemented and incorporated. Conversely, algorithmic advances alone are inert without the scale to also make them scary.
Source
The employee describes how solutions found in research are easy and quick to implement into current or next generation models. It's not like pharmaceutical research where breakthroughs take 10 years to reach the market, they can be implemented almost immediately. Furthermore, as noted in my blog post here, the massive investment currently underway in AI compute power is likely to push this even further ahead. For numbers, this video by AI Explained, estimates that between Q1 2024 and Q4 2025, ~2 years, there will be a roughly 14x increase in available compute.
So, as hinted above, my guess is that we will probably see widely available 1M context windows within a year. 1 billion is difficult to estimate for a non-expert like me, but I doubt it's far off.
Diminished Entrepreneurial Opportunities for Custom Models
There has been a lot of discussion over the past 12 months about the opportunities that exist for custom-trained or fine-tuned AI applications. For example, here's an interesting video from Andrew Ng, co-founder of Google Brain, on the topic.
However, while there will definitely be opportunities for super niche applications, I think opportunities for most general widespread uses are not going to be well-defensible positions. If the key value driver of an AI solution comes from using OpenAI or Google's AI API, then it's not going to be difficult to replicate the product.
In other cases where training a custom LLM model seems attractive today, in a short amount of time it will be simply much easier and cost-effective to use a big model with a huge context window and point it at all your data, rather than spending resources training a custom model for your specific use case.
Overall Market Perspective
So overall, I think once these context windows become sufficiently large, we will likely start to see many of the economic gains that are being promised by generative AI, such as vastly more efficient workers and the need for a smaller workforce. Businesses with large labor costs, particularly those that rely on knowledge workers, will probably benefit first from the ability to reduce headcount. But, the more I learn about this technology the more impressed I am with its ability to be used across so many domains.
The most likely outcome in my opinion at this time is that most of the profits from the enterprise application layer and developer tool layers of the industry will likely accrue to just a few major companies, similar to what we see in cloud computing. Where much of the world runs on Microsoft Azure, Amazon Web Services, or Google Cloud, I think we will see the same with enterprise AI systems that depend mostly on text. Ultimately, for application providers to effectively compete, they'll need to use the best, or most cost-effective, AI models available which are likely to come from the big tech companies with access to huge pools of data and compute power. Without using the best models, they'll be outcompeted by someone who does, but at the same time everyone who does use these models will be using the same model to drive value. I struggle to see where the ability to substantively hold a market positions lies, other than through being first-to-market in an area and capturing the network effects associated with it.
Conclusion
The rapidly increasing context window sizes of large language models like Claude 3 and those from Google and OpenAI have profound implications. While the release of models with context windows of 1 million may not be as attention-grabbing as OpenAI's Sora video generation, these advancements hint more strongly at the disruptive impact of AI in the office and associated costs.
The relative ease of implementing research breakthroughs into existing models combined with the giant wave of compute investment currently underway, suggests that effective limitations to these context windows is likely to go away very soon.
The impact of such vast context windows is that these language models could potentially comprehend entire organizational systems, like its accounting infrastructure, without the need for large investments in training a model on proprietary data.
As these capabilities become more accessible, it's difficult to truly predict their impact, other than the fact that businesses with high white-collar labor costs stand to make a lot of money in the short-term. In the long term, it will be difficult though for most of these businesses to sustain a competitive advantage if they are all just running on the same systems and thus capable of identical services. The gains then, will likely flow upwards to AI providers, and then their suppliers. Ultimately, as context windows exponentially increase, the AI industry's gravitational centre is likely to shift even further towards the handful of tech giants with the resources to create and democratize use of these ultra-large language models. How it affects everyone else is yet to be determined.